系列博文
- 在Linux上使用Kubeadm工具部署Kubernetes
- 带你玩转Docker
- Kubernetes集群之搭建ETCD集群
- Kubernetes集群之Dashboard
- Kubernetes集群之Monitoring
- Kubernetes集群之Logging
- Kubernetes集群之Ingress
- Kubernetes集群之Redis Sentinel集群
- Kubernetes集群之Kafka和ZooKeeper
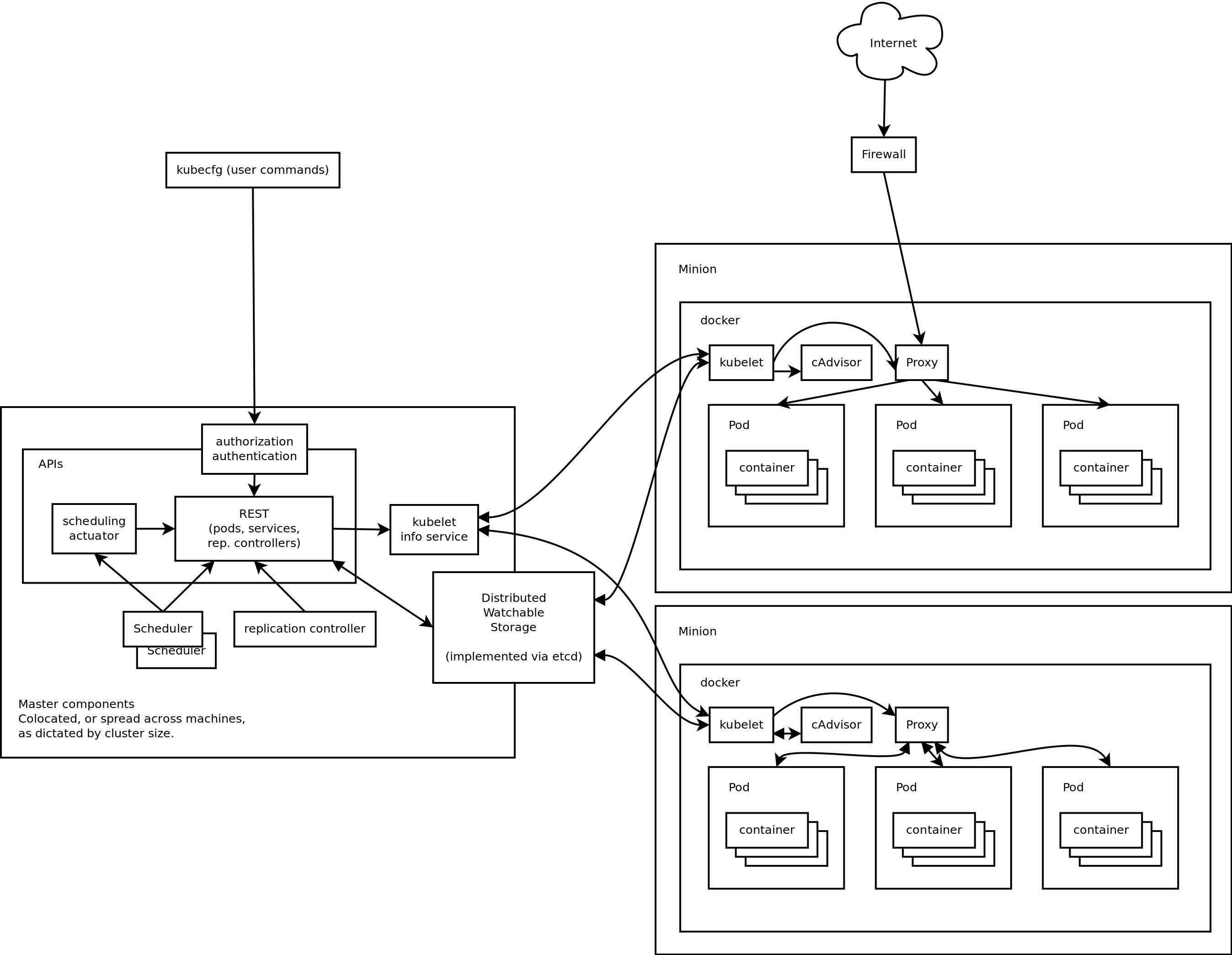
Kubernetes框架
系统环境与IP
-
系统环境:
-
之前使用ubuntu16.04.1-desktop-amd64, 使用清华的源
-
随后使用centos7-server(推荐)
-
-
集群信息:
Node IP Master 192.168.1.167 Node 192.168.1.168 Node 192.168.1.169
整个环境在VM下完成,可用master克隆出两个子机
注意VM的网络设置。发现只有weave网络能在虚拟机中使用,但是flannel,calico和weave均能在物理机上使用,即DNS解析没有问题
以下开始的所有操作,在192.168.1.167单点中的root权限下操作
CentOS7系统备份与还原
当使用centos7-server时,为避免重复装系统,则采用备份复原的方式。
备份:
sudo su
cd /
tar cvpzf backup.tgz --exclude=/proc --exclude=/backup.tgz --exclude=/mnt --exclude=/sys /
# 或者
tar cvpjf backup.tar.bz2 --exclude=/proc --exclude=/backup.tar.bz2 --exclude=/mnt --exclude=/sys /
系统恢复:
tar xvpfz backup.tgz -C /
# 或者
tar xvpfj backup.tar.bz2 -C /
mkdir proc
mkdir lost+found
mkdir mnt
mkdir sys
部分软件安装
Ubuntu16.04
-
安装VIM:
sudo apt-get install vim -y -
安装SSH:
sudo apt-get install openssh-server- 启动SSH:
sudo service ssh start
- 启动SSH:
-
安装GIT:
sudo apt-get install git -y
CentOS7
-
sudo yum update -
关闭firewalls等:
sudo systemctl disable firewalld
sudo systemctl stop firewalld
sudo yum install -y ebtables
# setenforce是Linux的selinux防火墙配置命令 执行setenforce 0 表示关闭selinux防火墙。
sudo setenforce 0
centos7以firewalld代替iptables,我们可以关闭自带的firewalld,启动iptables
sudo yum install -y iptables
sudo yum update iptables
sudo yum install -y iptables-services
DOCKER安装与设置
安装kubernets之前的准备
修改Linux主机名
Ubuntu16.04
由于在VM下进行master的克隆,则需要对新子机进行重新修改主机名:
sudo vim /etc/hostname修改为想要的
192-168-1-167.master
sudo vim /etc/hosts,改第二行127.0.1.1 administrator167
127.0.0.1 localhost
127.0.1.1 192-168-1-167.master
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
- 重启计算机即可:
sudo reboot
CentOS7
ipname=192-168-1-167
nodetype=master
echo "${ipname}.${nodetype}" > /etc/hostname
echo "127.0.0.1 ${ipname}.${nodetype}" >> /etc/hosts
sysctl kernel.hostname=${ipname}.${nodetype}
制作kubelet kubeadm kubectl kubernetes-cni
Ubuntu16.04
由于网络缘故,无法直接像官网中的操作中直接apt-get install,所以需要自己制作所需的安装包。
查看自己的系统信息:
lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 16.04.1 LTS
Release: 16.04
Codename: xenial
需要从kubernetes/release中间开始制作:
-
git clone https://github.com/chenjian158978/release.git -
cd release -
docker build --tag=debian-packager debian -
docker run --volume="$(pwd)/debian:/src" debian-packager
其中第3,4步要等好长时间,然后在
debian/bin中找xenial文件夹。
目前来说,第四步失败,报错为无法访问国外的网站,与漠大神的交流中感觉还是需要个梯子,制作四个deb文件就是为了安装,所以通过梯子,很快的安装好了。
-
在ubuntu16.04上安装L2TP,详见文献参考;
-
登上梯子,这个不叙述。若想知道方法,请留言或gmail;
-
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - -
cat <<EOF > /etc/apt/sources.list.d/kubernetes.list deb http://apt.kubernetes.io/ kubernetes-xenial main EOF -
apt-get update -
apt-get install -y kubelet kubeadm kubectl kubernetes-cni
相关下载的deb文件可以从这里下载,然后通过
sudo dpkg -i *即可安装完毕
为避免再次下载这些deb文件,可以将其保存,其中
apt install的包位置如下:
ll /var/cache/apt/archives/kube*.deb
-rw-r--r-- 1 root root 12165700 12月 8 20:49 /var/cache/apt/archives/kubeadm_1.5.0-alpha.2-421-a6bea3d79b8bba-00_amd64.deb
-rw-r--r-- 1 root root 10292542 12月 8 20:44 /var/cache/apt/archives/kubectl_1.4.4-00_amd64.deb
-rw-r--r-- 1 root root 15701146 12月 8 20:37 /var/cache/apt/archives/kubelet_1.4.4-01_amd64.deb
-rw-r--r-- 1 root root 6873078 12月 8 20:32 /var/cache/apt/archives/kubernetes-cni_0.3.0.1-07a8a2-00_amd64.deb
CentOS7
吸取了在ubuntu系统上的教训,直接通过梯子获得四个rpm的安装文件,相关链接为kubeadm-rpm,通过命令sudo yum install * -y即可安装完。
启动kubelet服务:
sudo systemctl enable kubelet && systemctl start kubelet
下载kubeadm需要的镜像(k8s版本为1.5.1)
| images name | version |
|---|---|
| gcr.io/google_containers/kube-discovery-amd64 | 1.0 |
| gcr.io/google_containers/kube-proxy-amd64 | v1.5.1 |
| gcr.io/google_containers/kube-scheduler-amd64 | v1.5.1 |
| gcr.io/google_containers/kube-controller-manager-amd64 | v1.5.1 |
| gcr.io/google_containers/kube-apiserver-amd64 | v1.5.1 |
| gcr.io/google_containers/etcd-amd64 | 3.0.14-kubeadm |
| gcr.io/google_containers/pause-amd64 | 3.0 |
| gcr.io/google_containers/kubedns-amd64 | 1.9 |
| gcr.io/google_containers/kube-dnsmasq-amd64 | 1.4 |
| gcr.io/google_containers/exechealthz-amd64 | 1.2 |
| gcr.io/google_containers/kubernetes-dadashboard-amd64 | v1.5.0 |
| gcr.io/google_containers/heapster_grafana | v3.1.1 |
| kubernetes/heapster | canary |
| kubernetes/heapster_influxdb | v0.6 |
| gcr.io/google_containers/fluentd-elasticsearch | 1.20 |
| gcr.io/google_containers/elasticsearch | v2.4.1 |
| gcr.io/google_containers/kibana | v4.6.1 |
查看私有库文件:
curl http://10.0.0.153:5000/v2/_catalog
{"repositories":["kube-apiserver-amd64","exechealthz-amd64","etcd-amd64","kube-controller-manager-amd64","kube-discovery-amd64","kube-dnsmasq-amd64","kube-proxy-amd64","kube-scheduler-amd64","kubedns-amd64","pause-amd64"]}
- 批量准备所需镜像
images=(kube-discovery-amd64:1.0 kube-proxy-amd64:v1.5.1 kube-scheduler-amd64:v1.5.1 kube-controller-manager-amd64:v1.5.1 kube-apiserver-amd64:v1.5.1 etcd-amd64:3.0.14-kubeadm pause-amd64:3.0 kubedns-amd64:1.9 kube-dnsmasq-amd64:1.4 exechealthz-amd64:1.2 dnsmasq-metrics-amd64:1.0)
for image in ${images[@]}; do
docker pull 10.0.0.153:5000/k8s/$image
docker tag 10.0.0.153:5000/k8s/$image gcr.io/google_containers/$image
docker rmi 10.0.0.153:5000/k8s/$image
done
kubeadm初始化
这里初始化参数是一次性全部写入,读者需要根据自己的需求来选择对应的参数。
kubeadm init --api-advertise-addresses 192.168.1.167 --use-kubernetes-version v1.5.1 --pod-network-cidr 10.244.0.0/16 --external-etcd-endpoints http://192.168.1.157:2379,http://192.168.1.158:2379,http://192.168.1.159:2379
Flag --external-etcd-endpoints has been deprecated, this flag will be removed when componentconfig exists
[kubeadm] WARNING: kubeadm is in alpha, please do not use it for production clusters.
[preflight] Running pre-flight checks
[preflight] Starting the kubelet service
[init] Using Kubernetes version: v1.5.1
[tokens] Generated token: "b54b79.c8c5e44532a817ff"
[certificates] Generated Certificate Authority key and certificate.
[certificates] Generated API Server key and certificate
[certificates] Generated Service Account signing keys
[certificates] Created keys and certificates in "/etc/kubernetes/pki"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/kubelet.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/admin.conf"
[apiclient] Created API client, waiting for the control plane to become ready
[apiclient] All control plane components are healthy after 16.880375 seconds
[apiclient] Waiting for at least one node to register and become ready
[apiclient] First node is ready after 5.526103 seconds
[apiclient] Creating a test deployment
[apiclient] Test deployment succeeded
[token-discovery] Created the kube-discovery deployment, waiting for it to become ready
[token-discovery] kube-discovery is ready after 680.505062 seconds
[addons] Created essential addon: kube-proxy
[addons] Created essential addon: kube-dns
Your Kubernetes master has initialized successfully!
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
http://kubernetes.io/docs/admin/addons/
You can now join any number of machines by running the following on each node:
kubeadm join --token=b54b79.c8c5e44532a817ff 192.168.1.167
- 记住token的值,这个在后续需要。如果你丢失了,可使用以下命令:
kubectl -n kube-system get secret clusterinfo -o yaml | grep token-map | awk '{print $2}' | base64 -d | sed "s|{||g;s|}||g;s|:|.|g;s/\"//g;" | xargs echo
- 如果init失败,下一次开始前输入:
kubeadm reset
docker rm `docker ps -a -q`
find /var/lib/kubelet | xargs -n 1 findmnt -n -t tmpfs -o TARGET -T | uniq | xargs -r umount -v
rm -r -f /etc/kubernetes /var/lib/kubelet /var/lib/etcd
-
--api-advertise-addresses 192.168.1.167设置指定的网络接口 -
--use-kubernetes-version v1.4.6设置k8s的版本 -
--pod-network-cidr 10.244.0.0/16设置指定的网段(Flannel需要) -
--external-etcd-endpoints http://192.168.1.157:2379,http://192.168.1.158:2379,http://192.168.1.159:2379设置外部的etcd集群.目前使用kubeadm不支持HA,即etcd集群,只支持单节点的etcd
pod网络创建
网络方式有多种选择。如果k8s集群建在虚拟机中,可以使用weave(较为稳定),或者flannel(有部分问题);如果k8s集群创建在实体机中,建议是用calico(最好的选择)
采用Flannel:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
这里会pull镜像quay.io/coreos/flannel-git:v0.6.1-28-g5dde68d-amd64,其托管在quay.io上,不需要梯子
但尽量先pull好镜像,并且整理好经常使用的yaml文件,可以节省时间
读者想要对应的yaml文件,可到这里进行下载。
查看集群状态
kubectl get pods --all-namespaces -o wide
当状态均为Running,到此,单节点的k8s的master已经搭建完成
添加节点
使用虚拟机前提下的说明
-
添加节点
192.168.1.168的虚拟机,直接克隆192.168.1.167,然后改IP; -
修改主机名,详细见上文;
-
停止克隆的集群服务
3.1
kubeadm reset3.2
systemctl start kubelet.service3.3
docker rm `docker ps -a -q` -
重启
167机器后发现:
root@administrator167:/home/administrator# kubectl get pods --all-namespaces
The connection to the server localhost:8080 was refused - did you specify the right host or port?
这时候,重启一下机器
kubeadm join
在192.168.1.168上操作:
kubeadm join --token=e3b02c.5c85004416c2370c 192.168.1.167
Running pre-flight checks
<util/tokens> validating provided token
<node/discovery> created cluster info discovery client, requesting info from "http://192.168.1.167:9898/cluster-info/v1/?token-id=e3b02c"
<node/discovery> cluster info object received, verifying signature using given token
<node/discovery> cluster info signature and contents are valid, will use API endpoints [https://192.168.1.167:6443]
<node/bootstrap> trying to connect to endpoint https://192.168.1.167:6443
<node/bootstrap> detected server version v1.4.6
<node/bootstrap> successfully established connection with endpoint https://192.168.1.167:6443
<node/csr> created API client to obtain unique certificate for this node, generating keys and certificate signing request
<node/csr> received signed certificate from the API server:
Issuer: CN=kubernetes | Subject: CN=system:node:administrator168 | CA: false
Not before: 2016-12-10 05:53:00 +0000 UTC Not After: 2017-12-10 05:53:00 +0000 UTC
<node/csr> generating kubelet configuration
<util/kubeconfig> created "/etc/kubernetes/kubelet.conf"
Node join complete:
* Certificate signing request sent to master and response
received.
* Kubelet informed of new secure connection details.
Run 'kubectl get nodes' on the master to see this machine join.
到此,两台k8s的集群已经搭建完成
Kubectl的基本命令
查看集群信息
kubectl cluster-info
查看集群master节点功能
kubectl get componentstatuses
查看集群节点信息
kubectl get nodes --show-labels
描述某个节点的信息
kubectl describe node 10-0-0-171.node
查询全部pod信息
kubectl get pods -o wide --all-namespaces
查看全部svc信息
kubectl get svc --all-namespaces -o wide
查看全部deployments信息
kubectl get deployments --all-namespaces
查看全部ingress信息
kubectl get ingresses --all-namespaces
查看全部secret信息
kubectl get secret --all-namespaces
查看全部pv信息
kubectl get pv
查看全部pvc信息
kubectl get pvc --all-namespaces
查看全部job信息
kubectl get job --all-namespaces -o wide
查看某pod的yaml文件内容
kubectl get pod weave-net-xhh0h --namespace=kube-system -o yaml
描述某pod的运行状态
kubectl describe pod calico-etcd --namespace=kube-system
描述某svc的运行状态
kubectl describe svc kube-dns --namespace=kube-system
描述某deployments的运行状态
kubectl describe deployments sitealive --namespace=cluster2016
删除某pod
kubectl delete pod sitealive-3553544168-q4gtx --namespace=wmcluster2016
查询某pod的log
kubectl logs proxycrawler-2347617609-mwzts --namespace=wmcluster2016
进去某pod的容器
kubectl exec -it busybox -- sh
# ubuntu系统
kubectl exec -it ubuntu-system -- /bin/bash
在某pod的容器中执行一段命令
kubectl exec -it busybox -- nslookup kubernetes.default
更新某deployments的replicas
kubectl scale deployments sitealive --namespace=cluster2016 --replicas=25
为某个node添加tag
kubectl label nodes administrator167 master=heapster-master
添加namespace
kubectl create namespace cludfdfdf20d
Troubleshooting
Node status is NotReady
- 某些节点失败
kubectl get nodes
NAME STATUS AGE
192.168.1.157 NotReady 42d
192.168.1.158 Ready 42d
192.168.1.159 Ready 42d
- 查看详细信息
kubectl describe node 192.168.1.157
......
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
OutOfDisk Unknown Sat, 28 May 2016 12:56:01 +0000 Sat, 28 May 2016 12:56:41 +0000 NodeStatusUnknown Kubelet stopped posting node status.
Ready Unknown Sat, 28 May 2016 12:56:01 +0000 Sat, 28 May 2016 12:56:41 +0000 NodeStatusUnknown Kubelet stopped posting node status.
......
从中可以看到节点unready的原因是outofdisk,从而导致Kubelet stopped posting node status.
所以可以查看下192.168.1.157的容量,其操作系统是ubuntu14.04,可通过df进行查看:
df
Filesystem 1K-blocks Used Available Use% Mounted on
udev 2008212 4 2008208 1% /dev
tmpfs 403856 3784 400072 1% /run
/dev/sda1 12253360 10108744 1499140 88% /
none 4 0 4 0% /sys/fs/cgroup
none 5120 0 5120 0% /run/lock
none 2019260 256 2019004 1% /run/shm
none 102400 40 102360 1% /run/user
然后通过docker rmi image来删除一些没用的镜像
- 重启kubelet
ssh [email protected]
sudo su
/etc/init.d/kubelet restart
stop: Unknown instance:
kubelet start/running, process 59261
- 查看节点
kubectl get nodes
NAME STATUS AGE
192.168.1.157 Ready 42d
192.168.1.158 Ready 42d
192.168.1.159 Ready 42d
恢复正常
Failed to create “kube-discovery” deployment
- 重新kubeadm init出现kube-discovery
failed to create "kube-discovery" deployment [deployments.extensions "kube-discovery" already exists]
问题在于外部的etcd集群内还有上一些的k8s集群信息,需要在每个etcd节点中删除数据,重启服务
rm -rf /var/lib/etcd/etcd0
if [[ true ]]; then
systemctl stop etcd
systemctl start etcd
systemctl status etcd
fi
在master上面重启k8s
systemctl stop kubelet
docker rm -f -v $(docker ps -q)
find /var/lib/kubelet | xargs -n 1 findmnt -n -t tmpfs -o TARGET -T | uniq | xargs -r umount -v
rm -r -f /etc/kubernetes /var/lib/kubelet /var/lib/etcd
systemctl start kubelet
kubeadm init xxxx
tcp 10.96.0.1:443: i/o timeout
-
在基本的k8s集群建立后,均为正常。开启一个服务(例如busybox),服务总出于ContainerCreating中。通过对node上的docker容器观察,一直处于pause容器创建过程中,问题是无法tcp连接到kubernetes服务的Apiserver(10.96.0.1:443)上
-
解决方法,在节点上添加:
route add 10.96.0.1 gw <your real master IP>
参考博文
- Installing Kubernetes on Linux with kubeadm
- 漠然博客
- ubuntu 16.04 L2TP
- Can not pull/push images after update docker to 1.12
- Tear down
- storage-schema
- influxdb
- 总结部署 Kubernetes+Heapster+InfluxDB+Grafana 详解
- Ubuntu16.04如何安装VMware Tools
- Installing Kubernetes Cluster with 3 minions on CentOS 7 to manage pods and services
- 基于 CentOS7 的 Kubernetes 集群
- Kubernetes 1.4.5
- centos7系统备份与还原
- CentOS7系统升级备份恢复实验
- Kibana4指南
- elasticsearch + fluentd + kibana4(EFK) 安裝詳細流程 in ubuntu14.04
- Kibana4学习三
- How to fix weave-net CrashLoopBackOff for the second node?
 本作品由陈健采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品由陈健采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。