性能优化
主要分为BIOS优化与虚机优化
BIOS优化
Intel超线程技术
-
全称:Intel Hyper-Threading
-
物理CPU核数:4个
-
逻辑CPU核数:物理CPU核数*2 = 8个
-
一个CPU可以跑两个线程,类似于1个CPU核变成了2个CPU核
-
通常会对程序有一个性能的提升,通常提升的范围大约在15%-30%之间,真实性能提升取决于具体的程序
| 一级项目 | 二级项目 | 三级项目 | 四级项目 |
|---|---|---|---|
| Advanced | CPU Configuration | Hyper-Threading(All) | Enable |
不同的BIOS系统,项目路径不尽相同。可以通过命令
dmidecode -t bios进行查看。
硬件辅助虚拟化技术
为弥补x86处理器的虚拟化缺陷,市场的驱动催生了VT-x,Intel推出了基于x86架构的硬件辅助虚拟化技术(Intel Virtualization Technology, Intel VT)。
目前,Intel VT技术包含CPU、内存和I/O三方面的虚拟化技术。
-
CPU硬件辅助虚拟化技术,分为
-
- 对应安腾架构的VT-i(Intel Virtualization Technology for ltanium)
-
- 对应x86架构的VT-x(Intel Virtualization Technology for x86)
-
- AMD AMD-V
-
内存硬件辅助虚拟化技术包括EPT(Extended Page Table)技术
- I/O硬件辅助虚拟化技术的代表VT-d(Intel Virtualization Technology for Directed I/O)
| 一级项目 | 二级项目 | 三级项目 | 四级项目 |
|---|---|---|---|
| Advanced | CPU Configuration | Intel Virtualization Technology | Enable |
x2apic
x2apic为Intel提供的xAPIC增强版,针对中断寻址、APIC寄存器访问进行改进优化。在虚拟化环境下,x2APIC提供的APIC寄存器访问优化对于性能有明显改进
| 一级项目 | 二级项目 | 三级项目 | 四级项目 |
|---|---|---|---|
| Advanced | CPU Configuration | X2APIC | Enable |
| Advanced | CPU Configuration | X2APIC_OPT_OUT Flag | Enable |
电源模式选项
关闭节能模式,打开性能模式
| 一级项目 | 二级项目 | 三级项目 | 四级项目 | 五级项目 |
|---|---|---|---|---|
| Advanced | CPU Configuration | Advanced Power Management Configuration | Power Technology (能源技术) | Custom(调试) |
| Advanced | CPU Configuration | Advanced Power Management Configuration | Energy Performance Tuning (能源性能调节) | Disable |
| Advanced | CPU Configuration | Advanced Power Management Configuration | Performance BIAS Setting(性能偏差设置) | Performance(高性能) |
| Advanced | CPU Configuration | Advanced Power Management Configuration | Energy Efficient Turbo(节能涡轮) | Enable |
CPU State Control
-
C1E Support
C1E(Enhanced Halt State)增强型空闲电源管理状态转换,一种可以令CPU省电的功能,开启后CPU在低负载状态通过降低电压与倍频来达到节电的目的
-
CPU C-State
CPU C-State是一项深度节能技术,其中C3、C6、C7的节能效果逐渐依次增强,但CPU恢复到正常工作状态的时间依次增加,设置C3 Report打开即支持C3节能,其他相同
-
Package C State limit
C状态限制:如果限制到C0,C1E就不起作用;如果限制到C2,就不能进入C3更节能状态;默认是自动的,超频时可以设置为No Limit(不限制)
| 一级项目 | 二级项目 | 三级项目 | 四级项目 | 五级项目 | 六级项目 |
|---|---|---|---|---|---|
| Advanced | CPU Configuration | Advanced Power Management Configuration | CPU C State Control | Package C State Limit | C0/C1 state |
| Advanced | CPU Configuration | Advanced Power Management Configuration | CPU C State Control | CPU C3 Report | Disable |
| Advanced | CPU Configuration | Advanced Power Management Configuration | CPU C State Control | CPU C6 Report | Disable |
| Advanced | CPU Configuration | Advanced Power Management Configuration | CPU C State Control | Enhanced Halt State (C1E) | Disable |
| Advanced | CPU Configuration | Advanced Power Management Configuration | CPU T State Control | ACPI T-State | Disable |
EIST自动降频
智能降频技术,它能够根据不同的系统工作量自动调节处理器的电压和频率,以减少耗电量和发热量。从而不需要大功率散热器散热,也不用担心长时间使用电脑会不稳定,而且更加节能。 EIST全称为“Enhanced Intel SpeedStep Technology”,是Intel开发的Intel公司专门为移动平台和服务器平台处理器开发的一种节电技术。
| 一级项目 | 二级项目 | 三级项目 | 四级项目 | 五级项目 | 六级项目 |
|---|---|---|---|---|---|
| Advanced | CPU Configuration | Advanced Power Management Configuration | CPU P State Control | EIST (P-States) | Disable |
VT-d
I/O硬件辅助虚拟化技术的代表VT-d(Intel Virtualization Technology for Directed I/O),是定向I/0虚拟化技术,开启了可以对虚拟机使用存储设备有提升
| 一级项目 | 二级项目 | 三级项目 | 四级项目 | 五级项目 | 六级项目 | 七级项目 |
|---|---|---|---|---|---|---|
| Advanced | Chipset Configuration | North Bridge | IIO Configuration | Intel Vt for Directed I/O (VT-d) | Intel Vt for Directed I/O (VT-d) | Enable |
NUMA
| 一级项目 | 二级项目 | 三级项目 | 四级项目 |
|---|---|---|---|
| Advanced | ACPI Settings | NUMA | Enabled |
虚拟机优化
电源管理
| 一级项目 | 二级项目 | 三级项目 | 四级项目 | 五级项目 | 六级项目 |
|---|---|---|---|---|---|
| 主机 | 管理 | 硬件 | 电源管理 | 更改策略 | 高性能 |
CPU
-
逻辑cpu(Logical Processor, Lcpu)
每个物理内核同时可以执行的线程数。同一时间,一个内核只能运行一个Lcpu。开启超线程技术(HT),可以有两个Lcpu,即可以同时运行两个任务。
核数(cores)与插槽(socket):
| 业务类型 | 核数与插槽 |
|---|---|
| 分布式业务 | 多插槽, 单核数 |
| 数据库 | 多插槽, 单核数 |
| 页面类型的网站 | 多核数, 单插槽 |
操作:
| 一级项目 | 二级项目 | 三级项目 |
|---|---|---|
| CPU热插拔 | 启用CPU热添加 | 对勾 |
| 硬件虚拟化 | 向客户机操作系统公开硬件辅助的虚拟化 | 对勾 |
| 限制 | 不受限制 | |
| CPU/MMU 虚拟化 | 硬件CPU和MMU |
grep 'HV Settings' /vmfs/volums/xxxxxx-xxxx-xxx-xxxx/vmware.log
<<'COMMENT'
2018-02-16T05:13:14.651z| vmxl I120: HV Settings: virtual exec = 'hardware'; virtual mmu = 'hardware'
COMMENT
内存
| 一级项目 | 二级项目 | 三级项目 |
|---|---|---|
| 限制 | 不受限制 | |
| 内存热插拔 | 已启用 | 对勾 |
磁盘
磁盘类型和区别:
-
厚置备,延迟置零
默认的创建格式,创建磁盘时,直接从磁盘分配空间,但对磁盘保留数据不置零。所以当有I/O操作时,只需要做置零的操作。
磁盘性能较好,时间短,适合于做池模式的虚拟桌面
-
厚置备,置零(thick):
创建群集功能的磁盘。创建磁盘时,直接从磁盘分配空间,并对磁盘保留数据置零。所以当有I/O操作时,不需要等待直接执行。
磁盘性能最好,时间长,适合于做跑运行繁重应用业务的虚拟机
-
精简置备(thin):
创建磁盘时,占用磁盘的空间大小根据实际使用量计算,即用多少分多少,提前不分配空间,对磁盘保留数据置零,且最大不超过划分磁盘的大小
所以当有I/O操作时,需要先分配空间,在将空间置零,才能执行I/O操作。当有频繁I/O操作时,磁盘性能会有所下降
I/O不频繁时,磁盘性能较好;I/O频繁时,磁盘性能较差。时间短,适合于对磁盘I/O不频繁的业务应用虚拟机
操作:
| 一级项目 | 二级项目 |
|---|---|
| 硬盘 | 厚置备置零 |
| 限制(IOPs) | 不受限 |
NUMA
SMP技术
SMP(Symmetric Multi-Processing)技术就是对称多处理结构,结构特点是CPU共享所有资源,比如总线,内存,IO系统等等。
由于共享所有的资源,各个CPU之间是平等的关系,操作系统管理着这些CPU对资源的访问(通常是用队列的形式去管理)。每个CPU依次的去处理队列中的进程,如果两个CPU同时访问,那么一般是通过软件锁的机制去解决争夺的问题,软件锁这概念跟开发里的线程安全锁机制道理是一样的,当一个CPU处理着一进程,一般会先锁住,处理完再释放。
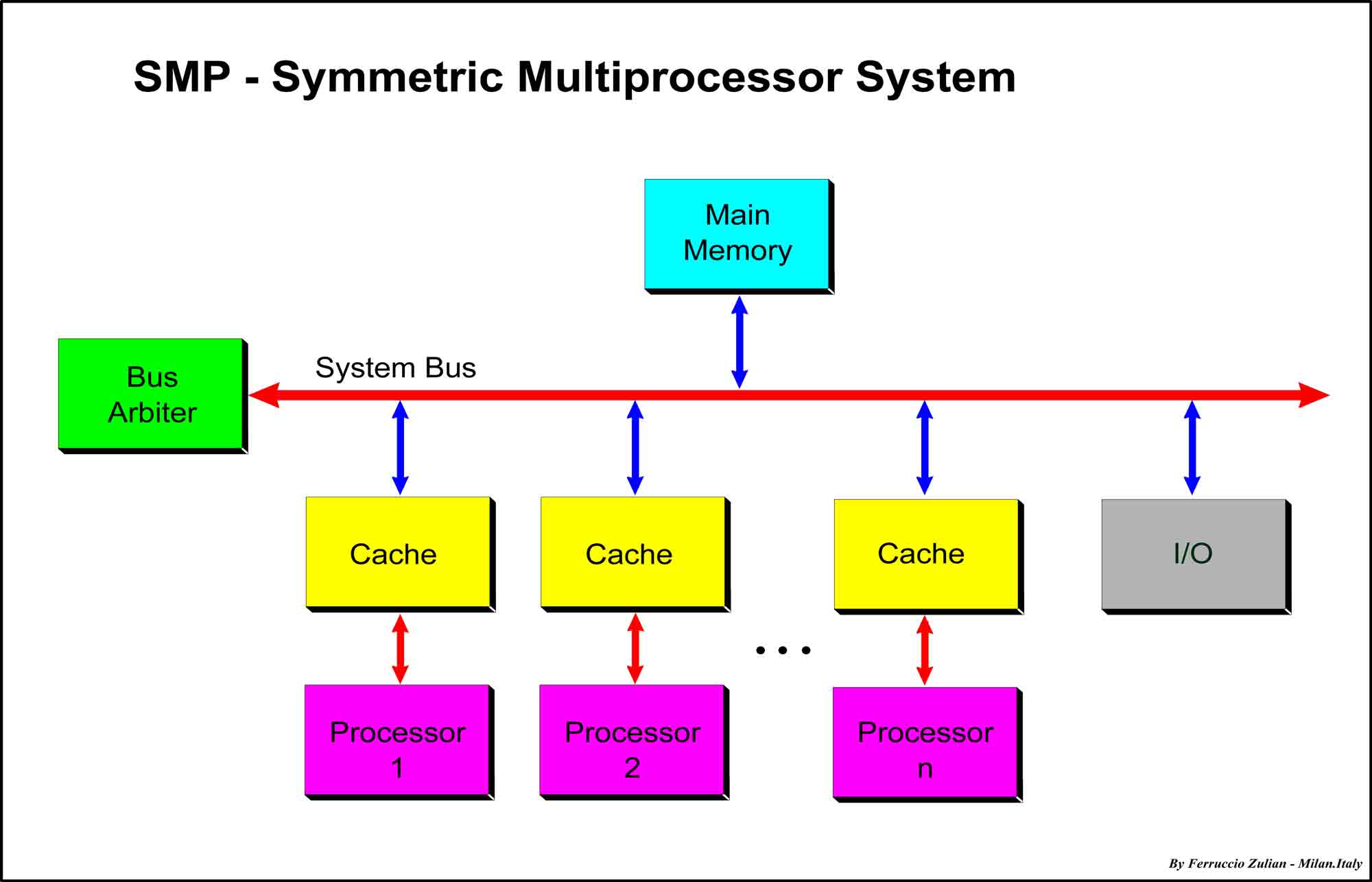
其弊端是扩展能力不强。如图所示,如果服务器要提升性能增加CPU,则内存(内存最大化的情况下)就明显不够了,因为是共享模式,多一个CPU就多一个吃内存数据的单元。因此多增加的CPU没法享受到内存的数据,就会停歇,从而造成了CPU的浪费。
有实验数据表明,SMP型的服务器CPU最好是2-4颗,多余的就浪费了。
NUMA技术
NUMA架构设计图:
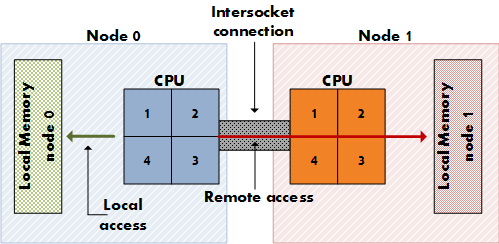
每个CPU模块之间都是通过互联模块进行连接和信息交互,CPU都是互通互联的,同时,每个CPU模块平均划分为若干个Chip(不多于4个),每个Chip都有自己的内存控制器(Memory controller)及内存插槽。
从硬件上来讲,numa node包含本地CPU和本地内存(Local CPU + Local Memory= NUMA Node),一个node内部的本地CPU访问本地内存,被称为本地访问(Local Access),通过跨插槽链接(Intersocket Connection)访问外部node中的本地内存,被称为远端访问(Remote Access)
-
本地节点:对于某个节点中的所有CPU,此节点称为本地节点
-
邻居节点:与本地节点相邻的节点称为邻居节点
-
远端节点:非本地节点或邻居节点的节点,称为远端节点
-
- 邻居节点和远端节点,都称作非本地节点(OffNode)。
CPU访问不同类型节点内存的速度是不相同的,本地访问节点速度最快,访问远端节点的速度最慢,即访问速度与节点的距离有关,距离越远访问速度越慢,此距离称作Node Distance。正是因为有这个特点,应用程序要尽量的减少不通CPU模块之间的交互,也就是说,如果应用程序能有方法固定在一个CPU模块里,其性能将会有很大的提升。
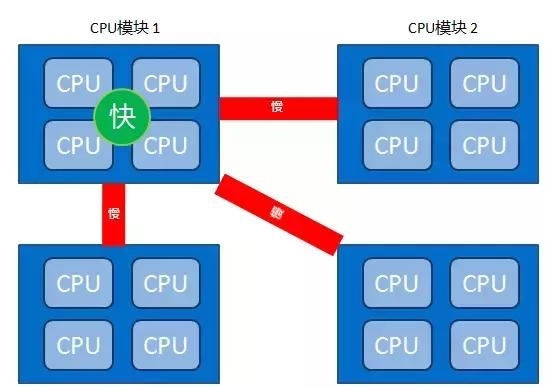
- 访问速度:
本地节点 > 邻居节点 > 远端节点
numa操作
# 判断是否开启NUMA
grep -i numa /var/log/dmesg
<<'COMMENT'
[ 0.000000] NUMA: Initialized distance table, cnt=2
[ 0.000000] NUMA: Node 0 [mem 0x000000-0x7fffff] + [mem 0x1000000-0x10ffffff] -> [mem 0x000000-0x107fffff]
[ 0.000000] Enabling automatic NUMA balancing. Configure with numa_balancing= or the kernel.numa_balancing sysctl
[ 2.504369] pci_bus 0000:00: on NUMA node 0
[ 2.542087] pci_bus 0000:80: on NUMA node 1
COMMENT
numactl --hardware
<<'COMMENT'
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 10 11 12 13 28 29 30 31 32 33
node 0 size: 62224 MB
node 0 free: 191 MB
node 1 cpus: 14 15 16 17 18 19 20 21 22 23 24 25 26 27
node 1 size: 65116 MB
node 1 free: 236 MB
node distances:
node 0 1
0: 10 11
1: 11 10
COMMENT
numastat
<<'COMMENT'
node0 node1
numa_hit 24470100 26469173
numa_miss 0 0
numa_foreign 0 0
interleave_hit 332 327
local_node 26981577 26412357
other_node 775 858
COMMENT
numastat -c test1
Per-node process memory usage (in MBs) for PID 305 (test1)
Node 0 Node 1 Total
------ ------ -----
Huge 0 0 0
Heap 5 3 9
Stack 0 0 0
Private 42 58 100
------- ------ ------ -----
Total 42 58 100
-
当numa_miss较高时,说明需要对分配策略进行调整。例如将指定进程关联绑定到指定的CPU上,从而提高内存命中率。
-
NUMA陷阱。当程序test绑定在NUMA的node0上运行,即使test占用完node0上的内存,也不会使用其他node上的内存,从而开始占用SWAP。建议设置
numactl --interleave=all。 -
- 例如命令:
numactl --interleave=all ${MONGODB_HOME}/bin/mongod --config conf/mongodb.conf
- 例如命令:
-
每个进程(或线程)都会从父进程继承NUMA策略,并分配有一个优先node。如果NUMA策略允许的话,进程可以调用其他node上的资源。
-
NUMA的CPU分配策略有
cpunodebind、physcpubind。 -
cpunodebind规定进程运行在某几个node之上。
-
physcpubind可以更加精细地规定运行在哪些核上
- NUMA的内存分配策略有
localalloc、preferred、membind、interleave。 -
localalloc规定进程从当前node上请求分配内存;
-
preferred比较宽松地指定了一个推荐的node来获取内存,如果被推荐的node上没有足够内存,进程可以尝试别的node;
-
membind可以指定若干个node,进程只能从这些指定的node上请求分配内存;
-
interleave规定进程从指定的若干个node上以RR(Round Robin 轮询调度)算法交织地请求分配内存。
热添加CPU
热添加CPU是指能够动态向运行中的系统添加CPU,从而避免关机导致服务停止。
目前支持热添加,不支持热删除
lscpu
<<'COMMENT'
...
Byte Order: xxxxxxx
CPU(s): 2
On-line CPU(s) list: 0-1
Thread(s) per core: 1
...
COMMENT
# 安装工具libvirt,适用于KVM
yum install -y libvirt
# 增加虚拟机的CPU核数,添加数目不得超过xml中的最大数目
virsh setvcpus VM-test 3 --live
# 激活该CPU
echo 1 > /sys/devices/system/cpu/cpu2/online
参考文献
- 多个CPU和多核CPU以及超线程
- ESXi性能系列之二 虚拟机CPU优化指南
- CPU硬件辅助虚拟化技术
- BIOS中关闭EIST(自动降频)方法
- Intel vt-d开启了有什么影响
- 最详细BIOS参数图解一
- 最详细BIOS参数图解二
- vmware的硬件选项里有关于虚拟化引擎的选项
- 服务器BIOS主要设置项目解说
- CPU纯软件全虚拟化技术
- CPU纯软件半虚拟化技术
- CPU硬件辅助虚拟化技术
- 虚拟化小白对VMcpu分配的理解
- 关于VMware 虚拟机磁盘类型和区别
- KVM性能优化之CPU优化
- kvm libvirt cpu 热添加
- NUMA的取舍与优化设置
- 内存控制器
- NUMA架构的CPU–你真的用好了么
- What if the VM Memory Config Exceeds the Memory Capacity of the Physical NUMA Node?
 本作品由陈健采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品由陈健采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。