三种系统架构 & 两种存储器共享方式
从系统架构来看,目前的商用服务器大体可以分为三类:
-
对称多处理器结构(SMP:Symmetric Multi-Processor)
-
非一致存储访问结构(NUMA:Non-Uniform Memory Access)
-
海量并行处理结构(MPP:Massive Parallel Processing)。
共享存储型多处理机有两种技术
-
均匀存储器存取(Uniform-Memory-Access,简称UMA)技术
-
非均匀存储器存取(Nonuniform-Memory-Access,简称NUMA)技术
UMA技术
UMA是并行计算机中的共享存储架构,即物理存储器被所有处理机均匀共享,对所有存储字具有相同的存取时间。每台处理机可以有私用高速缓存,外围设备也以一定形式共享。UMA技术适合于普通需求和多用户共享时间的应用,在时序要求严格的应用中,被用作加速单一大型程序的执行率。
NUMA技术
NUMA是用于多进程计算中的存储设计,存储读取取决于当前存储器与处理器的关联。在NUMA技术下,处理器访问本地存储器比非本地存储器(另一个处理器的本地存储器或者处理器共享的存储器)更快。
vNUMA
vNUMA消除了VM和操作系统之间的透明性,并将NUMA架构直通到VM的操作系统。值得一提的是,vNUMA在业内与NUMA同样盛名。对于一个广泛VM技术,VM运行的底层架构,VM的NUMA拓扑跨越多个NUMA节点。在启用了vNUMA的VM的初始功能之后,呈现给操作系统的架构是永久定义的,并且不能被修改。这个限制通常是正面的,因为改变vNUMA体系结构可能会导致操作系统的不稳定,但是如果VM通过vMotion迁移到带有不同NUMA架构的管理程序,则可能导致性能问题。值得一提的是,尽管大多数应用程序都可以利用vNUMA,但大多数VM都足够小,可以装入NUMA节点;最近对宽-VM支持或vNUMA的优化并不影响它们。
因此,客户操作系统或它的应用程序如何放置进程和内存会显著影响性能。将NUMA拓扑暴露给VM的好处是,允许用户根据底层NUMA架构做出最优决策。通过假设用户操作系统将在暴露的vNUMA拓扑结构中做出最佳决策,而不是在NUMA客户机之间插入内存。
NUMA的重要性
多线程应用程序需要访问CPU核心的本地内存,当它必须使用远程内存时,性能将会受到延迟的影响。访问远程内存要比本地内存慢得多。所以使用NUMA会提高性能。 现代操作系统试图在NUMA节点(本地内存+本地CPU=NUMA节点)上调度进程,进程将使用本地NUMA节点访问核心。ESXi还使用NUMA技术为广泛的虚拟机,当虚拟核心大于8时,将虚拟核心分布在多个NUMA节点上。当机器启动时,虚拟核心将被分发到不同的NUMA节点,它将提高性能,因为虚拟核心将访问本地内存。
总结
首当为一个虚拟内核分配了更多的虚拟Socket,或者一个虚拟Socket分配更多的虚拟内核时,这之间的差别并不影响NUMA节点数量。虚拟Socket只会影响您的软件许可证而不是性能。
测试
测试设备信息
| 型号 | 虚拟内核数量 | 虚拟Socket数量 | HT状态 | 逻辑内核数量 |
|---|---|---|---|---|
| HPE DL380 G8 | 10 | 2 | Active | 40 |
测试结果
| 测试序列 | 每个Socket的内核数量 | 虚拟Socket数量 | 总内核数量 | NUMA节点数量 |
|---|---|---|---|---|
| 1 | 1 | 10 | 10 | 1 |
| 2 | 10 | 1 | 10 | 1 |
| 3 | 1 | 11 | 11 | 2 |
| 4 | 1 | 20 | 20 | 2 |
| 5 | 1 | 21 | 21 | 3 |
每个Socket的内核数量
一个vCPU是一个虚拟CPU包(含有1个单核和该核所占的Socket)。每个Socket的内核数量便是控制这个行为,而默认的设置是1。每当你在VM添加一个vCPU,虚拟CPU便被添加,同样Socket数量也在添加。
NUMA开启的默认条件有两点:
- 虚拟机包含大于等于9个vCPU
- vCPU数目超过物理NUMA节点的核数(当采用高级设置
numa.vcpu.preferHT=TRUE,同步多线程(SMT)将被计算,而不是之前内核决定调度的选项)
在ESXi服务器上,使用如下命令:
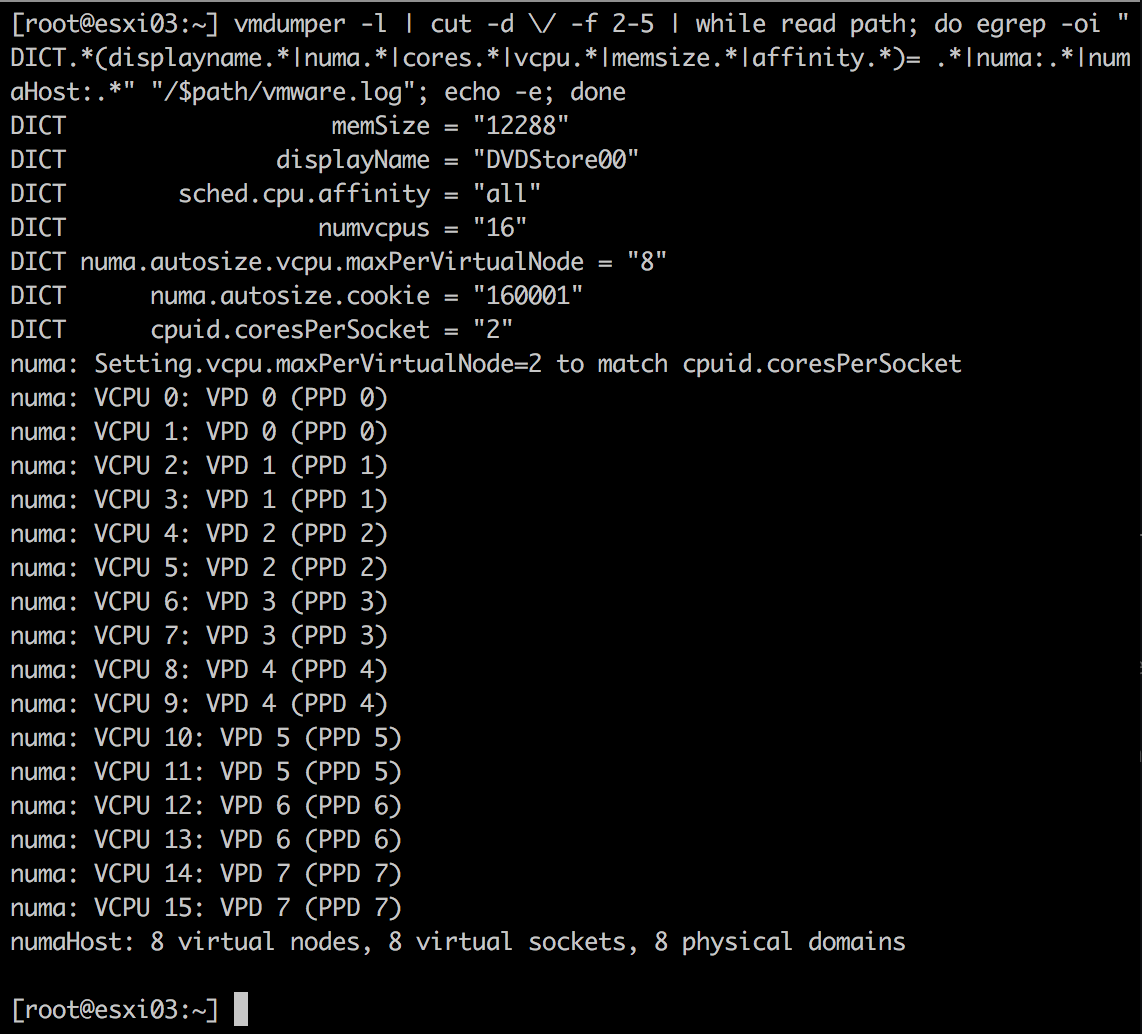
vmdumper -l | cut -d \/ -f 2-5 | while read path; do egrep -oi "DICT.*(displayname.*|numa.*|cores.*|vcpu.*|memsize.*|affinity.*)= .*|numa:.*|numaHost:.*" "/$path/vmware.log"; echo -e; done
实例1
在E5-2630 v4 ESXi 6.0设备上,有10个vCPU,命令结果如下:
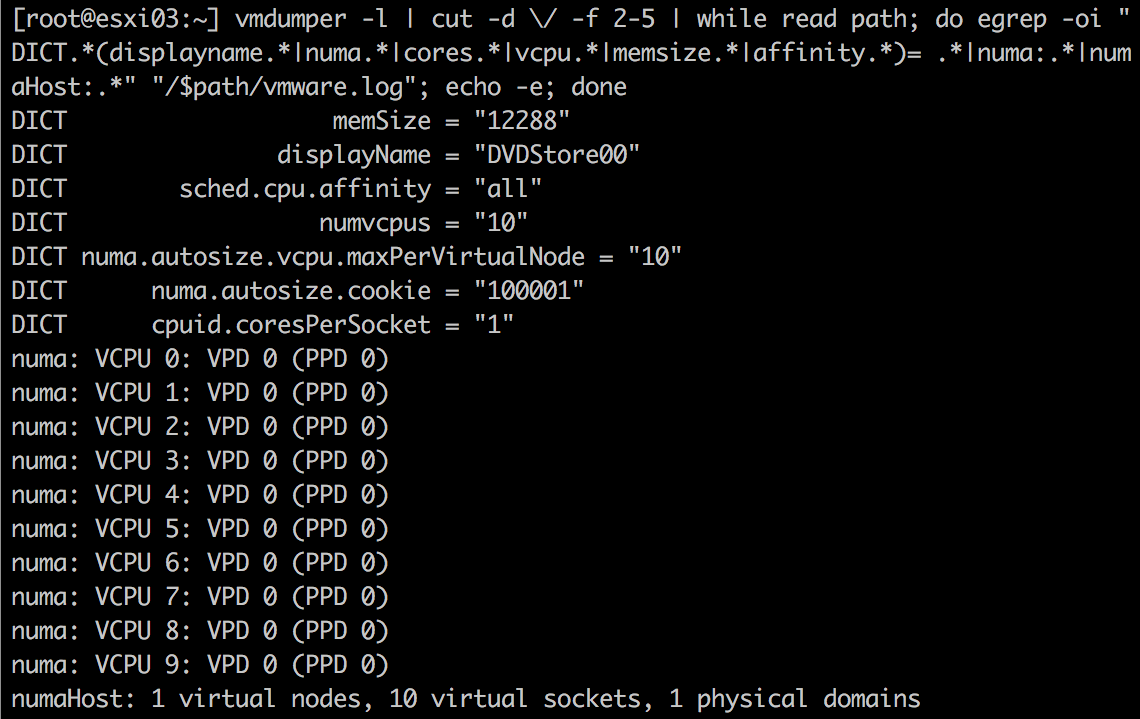
从上图可知:
- VM包含10个vCPU;
cupid.coresPerSocket = 1表明每个Socket包含1个内核;- numaHost表示10个vCPU将被打包到1个物理域名,即1个物理CPU包中,从而虚拟机上暴露出一个NUMA节点;
实例2
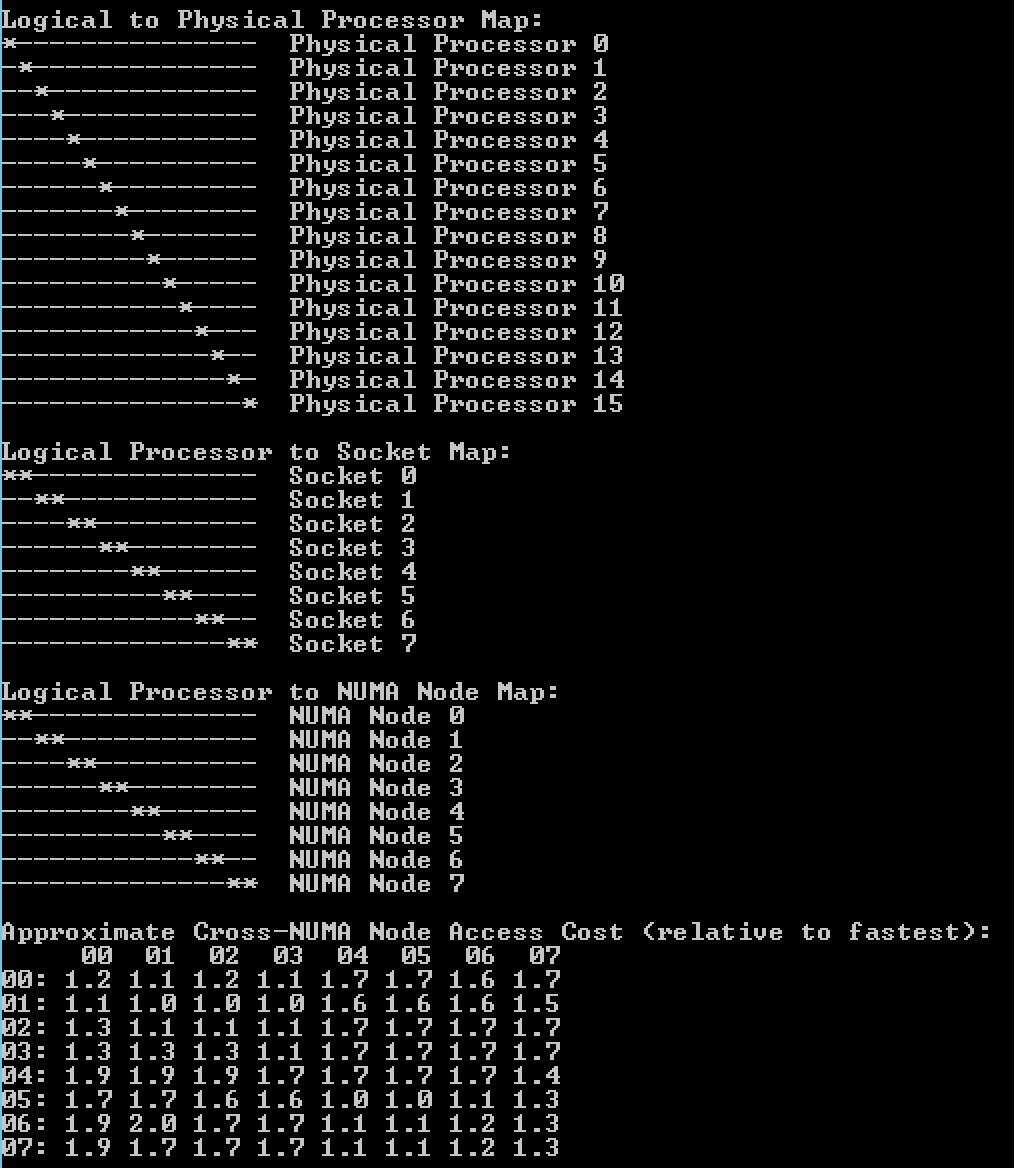
微软Sysinternals工具CoreInfo能够更详细的展示虚拟机中的CPU架构,Linux中包含numactl --hardware命令和lstopo -s命令来决定缓存配置。如下图所示:
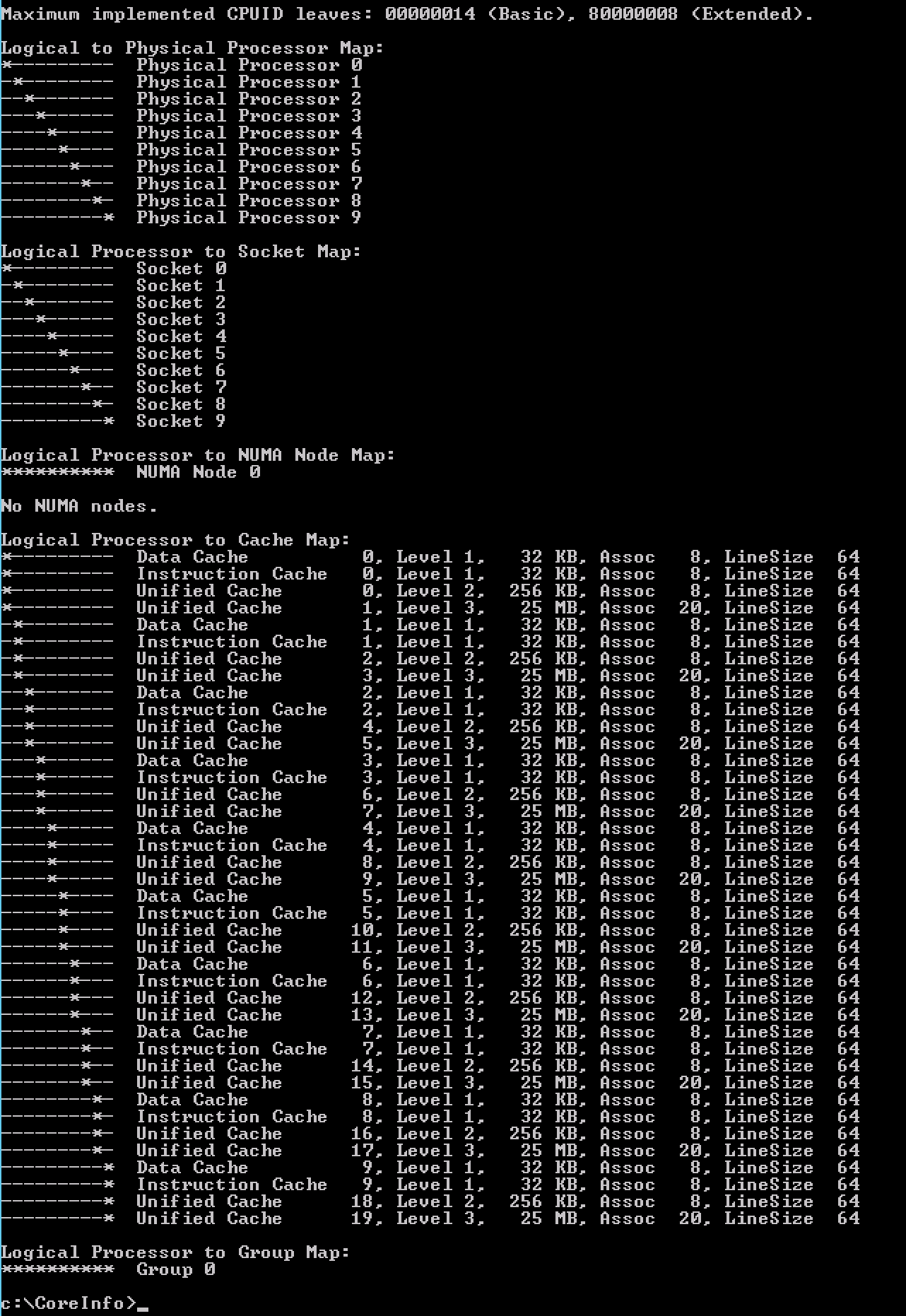
当VM的vCPU数量提升到16时,此时配置已经超过物理核数。微软Coreinfo工具提供的数据如下:
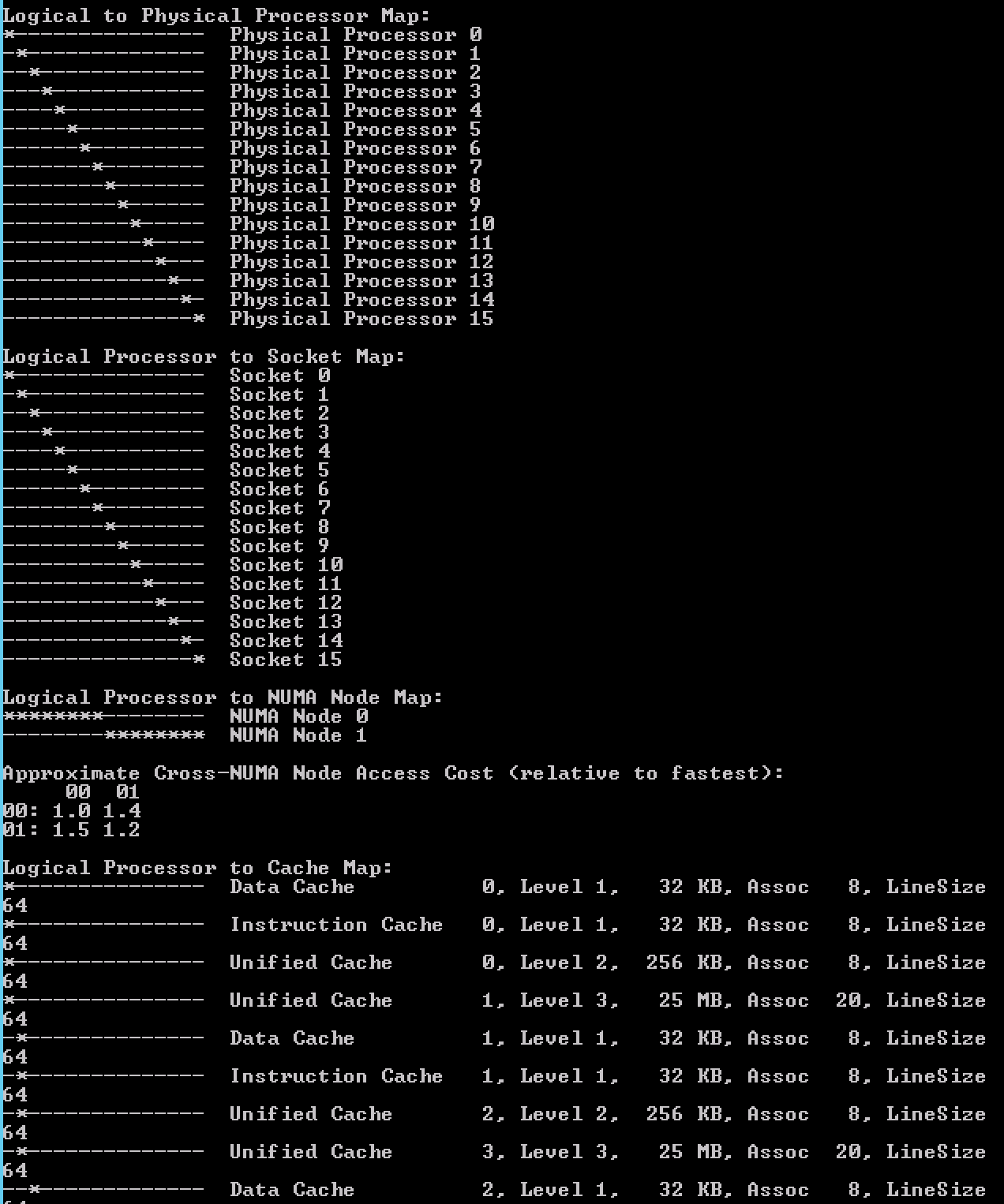
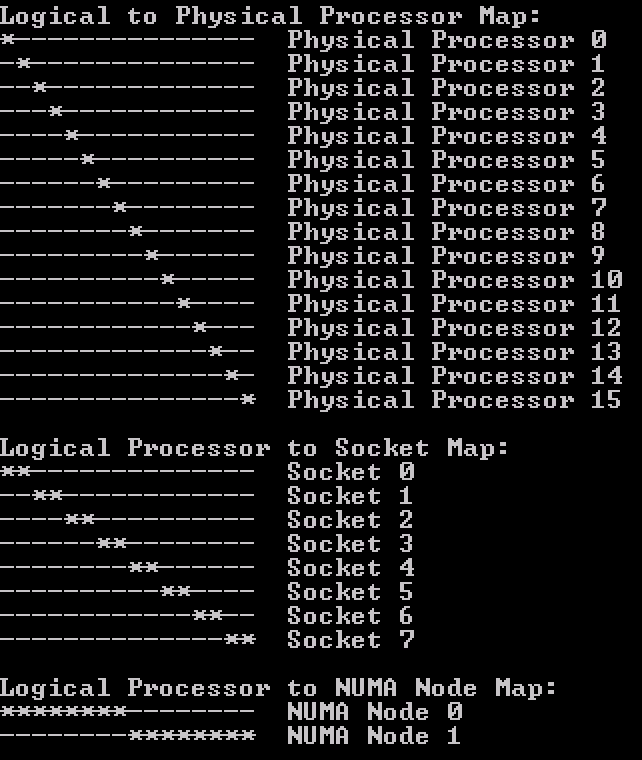
Coreinfo 采用*来展示“逻辑CPU-Socket”图表和“NUMA节点图表”。从上图中可以:
| NUMA节点序列 | Socket范围 |
|---|---|
| 0 | 0-7 |
| 1 | 8-15 |
在ESXi服务器上使用vmdumper命令,结果如下:
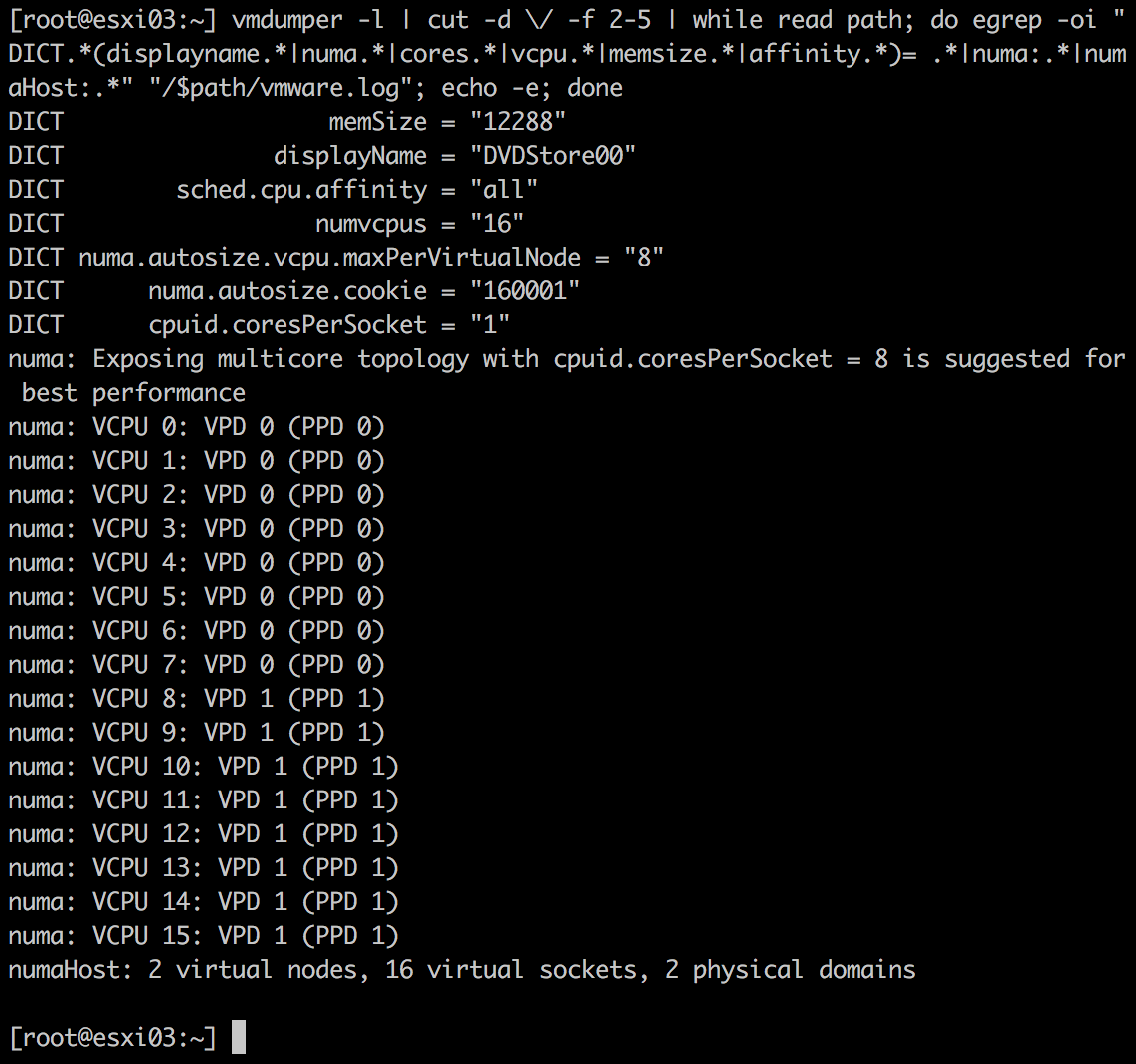
实例1与实例2的对比:
| 实例 | vCPU数量 | 参数 | NUMA节点数量 |
|---|---|---|---|
| 1 | 10 | numa.autosize.vcpu.maxPerVirtualNode = “10” | 1 |
| 2 | 16 | numa.autosize.vcpu.maxPerVirtualNode = “8” | 2 |
说明VM内核对称将16个vCPU分在两个NUMA节点中,它试图将更多更合适的vCPU数量分到最少的NUMA节点中,因此会出现每个节点中包含8个vCPU,似乎是表明使用参数为numa.autosize.vcpu.maxPerVirtualNode = "8"对多核技术能提供最佳性能。
VPD与PPD
虚拟NUMA技术包含两个因素:
- 虚拟邻近域名(Virtual Proximity Domains, VPD),将NUMA技术暴露在虚拟机上的结构
- 物理邻近域名(Physical Proximity Domains, PPD),将NUMA技术作为初始配置和负载均衡的结构
PPD基于CPU包的核数来自动设置每个物理CPU包中的最优vCPU数量。除非VM设置中已经设置了每个Socket的核数。在ESXI6.0中,“每个Socket的核数”的设置决定了PPD的大小,即vCPU数量等于物理CPU的核数。换句话说,PPD无法跨越多个物理CPU核。PPD如下图所示:

获得一个邻近域名的最佳方法是用它比较VM和寄主关联组(host affinity group),但是在这个案例中,是比较vCPU与CPU包资源。相对于CPU包中的所有CPU来说,PPD扮演了一个vCPU的关联组。一个邻近域名并不是自我调度的结构,它并不决定在物理资源中一个vCPU是否被调度,它只是确认一组特定的vCPU消费了特定的CPU包中的可使用资源。
VPD是将NUMA技术暴露在虚拟机上的结构。VPD数目取决于vCPU数目和物理核数,或者“每个Socket的核数”设置。默认上,VPD与PPD组成一体(VPD在PPD上层),如果一个包含16个vCPU的VM被创建,则会产生2个PPD。这些PPD允许VPD和VPD的vCPU组成一体,消费8核的CPU包。

如果使用了vCPU设置,这每个vCPU会被放到它自己的Socket(每个Socket的核数为1)中。在上图中,在VPD上面的深蓝色表示虚拟Socket,而浅蓝色表示vCPU。
如果没有使用默认的“每个Socket的核数”设置,则VPD到PPD的联盟可以被复写。如果vCPU数量和“每个Socket的核数”设置超过CPU包的物理核数,这VPD可以跨越多个PPD。
例如以下虚拟机:
| vCPU数量 | 每个Socket的核数 | CPU包数 | 每个CPU包中包含的核数 | VPD数量 | 每个VPD包含的vCPU | PPD数量 |
|---|---|---|---|---|---|---|
| 40 | 20 | 4 | 10 | 2 | 20 | 4 |
视图如下:

“每个Socket的核数”设置将会重写默认的VPD设置,如果物理布局并未正确的计算,则会导致性能下降。特别来讲,应该避免VPD跨越PPD。这种设置会导致寄主机上的绝大部分的CPU优化,而对于应用则毫无作用。例如,操作系统和应用程序可能会遇到远程内存访问延迟,而在优化线程位置之后期望本地内存延迟。
所以推荐设置虚拟机,“每个Socket的核数”与CPU包数的边界对齐。
ESXi6.5的“每个Socket的核数”
例如在ESXi6.0上,VM包含16CPU,每个Socket的核数为2,则会有8个VPD和8个PPD,如下图:
这里的问题就是,虚拟NUMA技术未能正确代表物理NUMA技术。

上图中,VM包含16个CPU,分布在8个Socket上,每个CPU包含它自己的缓存和自己的本地内存。操作系统则会认为来自其他CPU的内存地址为远程地址。OS必须基于NUMA调度最优化方案,来管理8小块的内存空间,并优化它的缓存管理和内存设置。从而,16个vCPU被分布到2个物理节点上,因此,8个vCPU共享相同的L3缓存并访问物理内存池。如下图:

通过CoreInfo得到的CPU设置如下:
为了避免本地内存的“破碎”,VPD的行为和它与“每个Socket的核数”的关系已被改变。在ESXi6.5中,VPD的大小与CPU包的核数是独立的。为了更接近于物理NUMA技术,才会更新VPD与PPD的虚拟NUMA技术。
在Intel Xeon E5-2630 v4上,ESXi版本为6.5,有20个核,创建16个vCPu,每个Socket的核数为2的虚拟机。使用vmdumper命令如下:
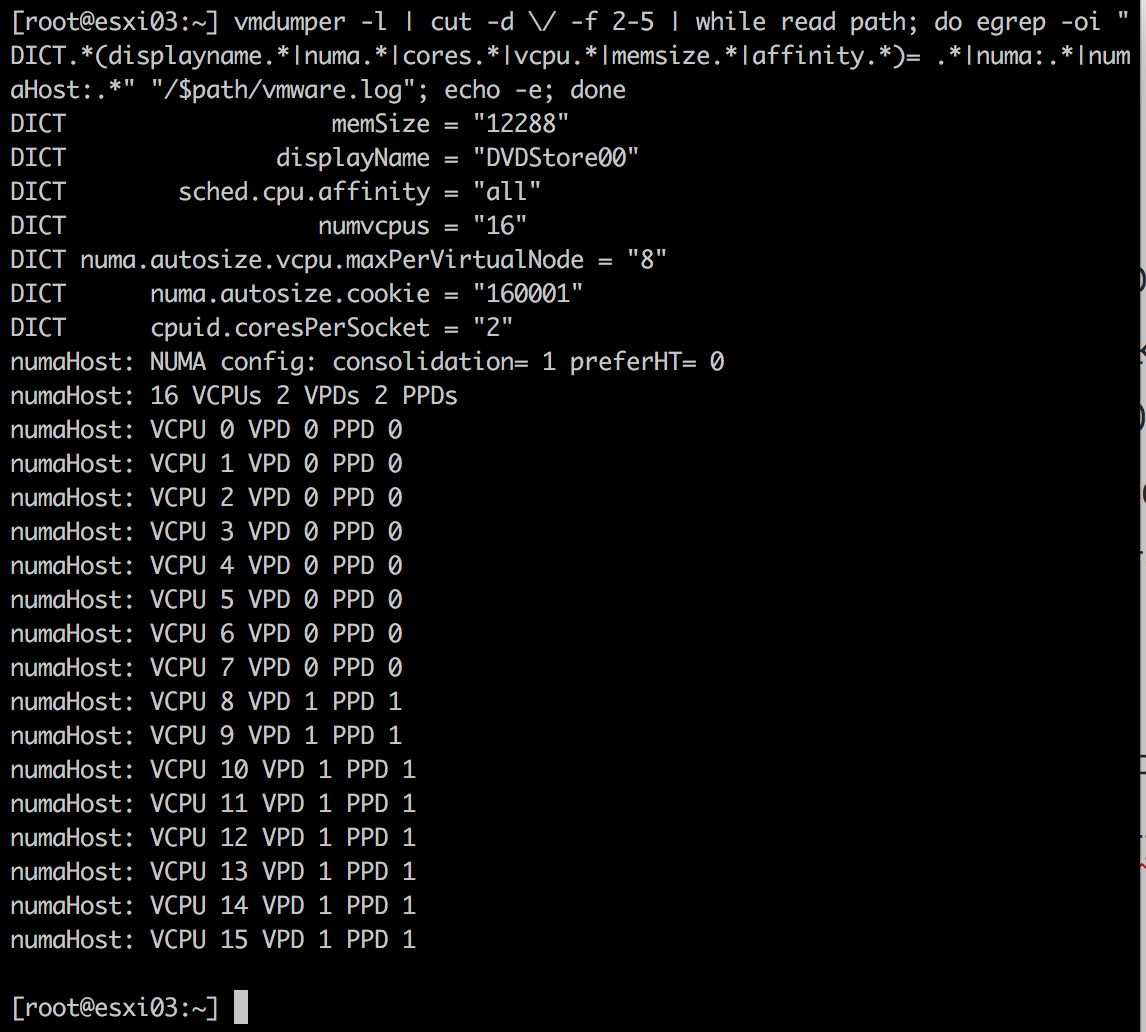
从结果中可以看到,虚拟机包含2个NUMA节点,只有2个PPD和VPD。注意,“每个Socket的核数”并未改变,从而在单个VPD中产生多个Socket。

在ESXi6.5中,NUMA config: consolidation =1表示vCPU将被合并进邻近域名中。在以下的例子中,16个vCPU将被分到2个NUMA节点中,因此会有2个VPD和PPD被创建。每个VPD暴露1个内存地址,与物理机器上的特质相连。

在虚拟机中运行Windows2012操作系统,会创建2个NUMA节点。任务管理界面如下:
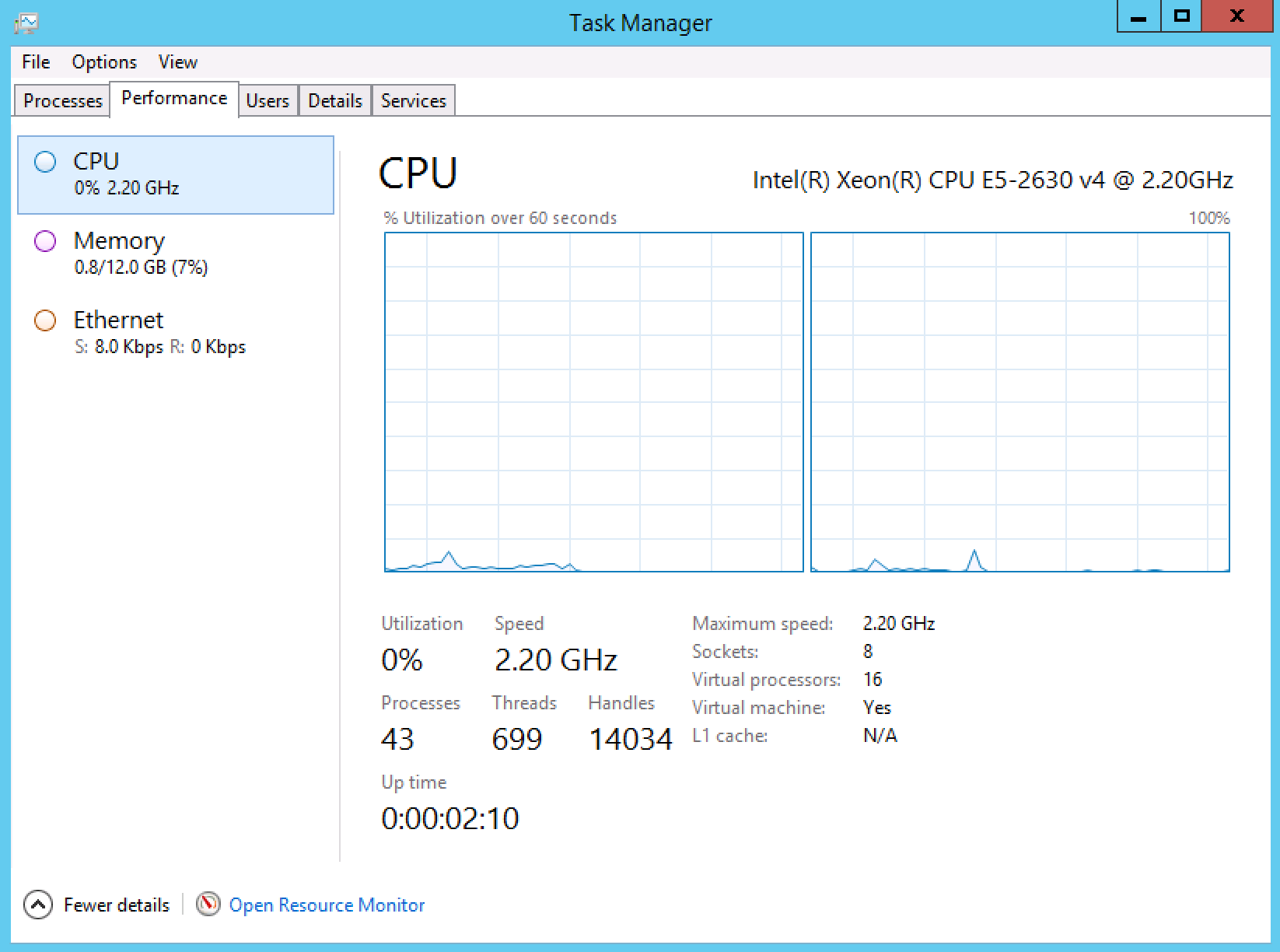
通过CoreInfo得到的CPU设置如下:
通过新的优化,虚拟NUMA技术更接近物理NUMA技术,允许操作系统正确优化进程访问本地和远程内存地址。
用户OS的NUMA优化
现代应用和操作系统读取内存主要基于NUMA节点(存储延迟)和缓存结构(共享数据)。很不幸的是绝大部分应用,即使是最佳优化的SMP架构,都没有完美的通过NUMA节点来负载均衡。现代的操作系统采取“邻近部署(First-Touch-Allocation)”策略,这意味着当应用读取内存时,虚拟地址并不对引导任何物理内存。当应用读取内存时,操作系统明显尽可能的将其连上本地内存或者特殊的NUMA。
理想的环境下,首次读取或者创建内存的线程,是处理它的线程。很不幸的是,大多数应用使用单线程环境,但在未来是多线程分布式的通过多个Socket来密集的访问数据。
如果VM并没有默认的“每个Socket的核数”设置,或者开启了高级设置numa.autosize.once = False,则开启高级设置Numa.FollowCoresPerSocket = 1
参考博文
- 服务器体系(SMP, NUMA, MPP)与共享存储器架构(UMA和NUMA)
- NUMA And vNUMA – Back To The Basic
- Decoupling of Cores per Socket from Virtual NUMA Topology in vSphere 6.5
- 重新启动一个虚拟机
 本作品由陈健采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品由陈健采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。